Results
Quantitative Results
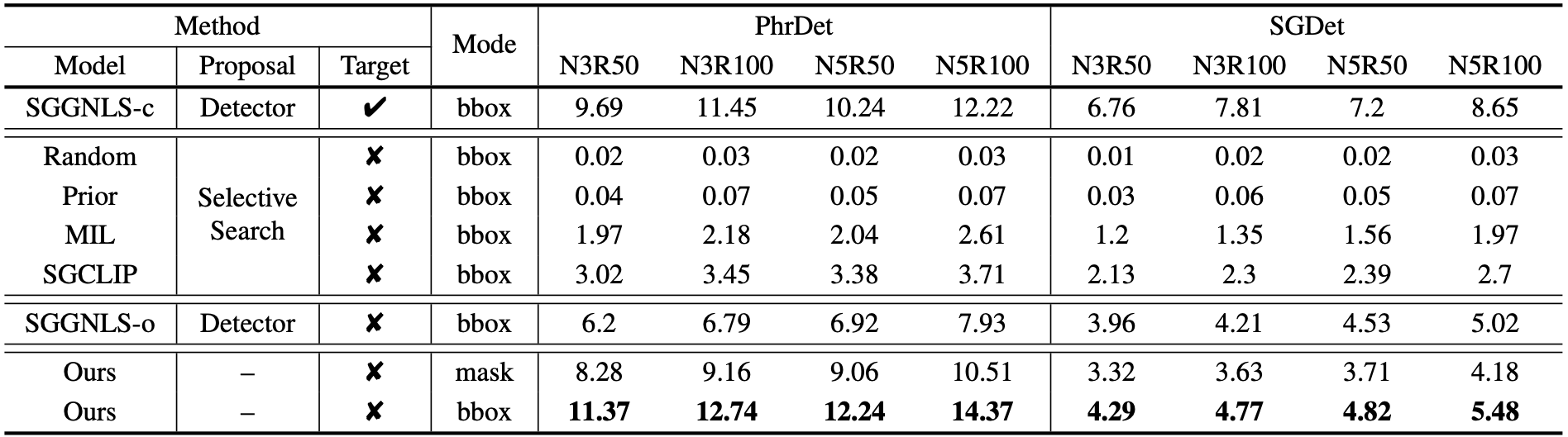
Our quantitative results on Caption-to-PSG are shown below.
To make a fair comparison with bbox-based scene graphs generated by baselines, we evaluate our generated PSGs in both mask and bbox mode.
For the latter, all masks in both prediction and ground truth are converted into bboxes (i.e., the mask area's enclosing rectangle) for
evaluation, resulting in an easier setting than the former. The results show that our framework (
Ours) significantly outperforms
all the baselines under the same constraints on both PhrDet (14.37 vs. 3.71 N5R100) and SGDet (5.48 vs. 2.7 N5R100). Our method also shows
better results compared with
SGGNLS-o on all metrics and all tasks (on PhrDet, 14.37 vs. 7.93 N5R100; on SGDet, 5.48 vs. 5.02 N5R100)
although
SGGNLS-o utilizes location priors by leveraging a pre-trained detector. The results demonstrate that our framework is more
effective for learning a good panoptic structured scene understanding.
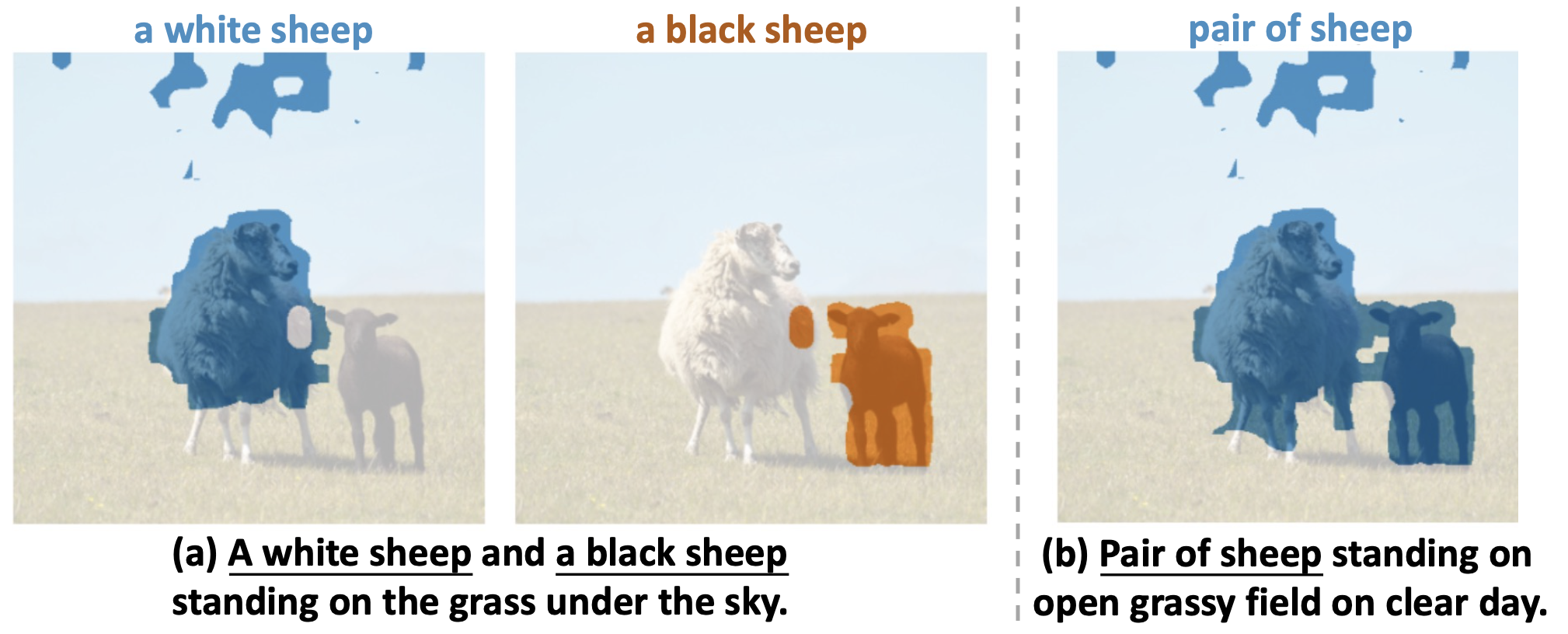
Qualitative Results
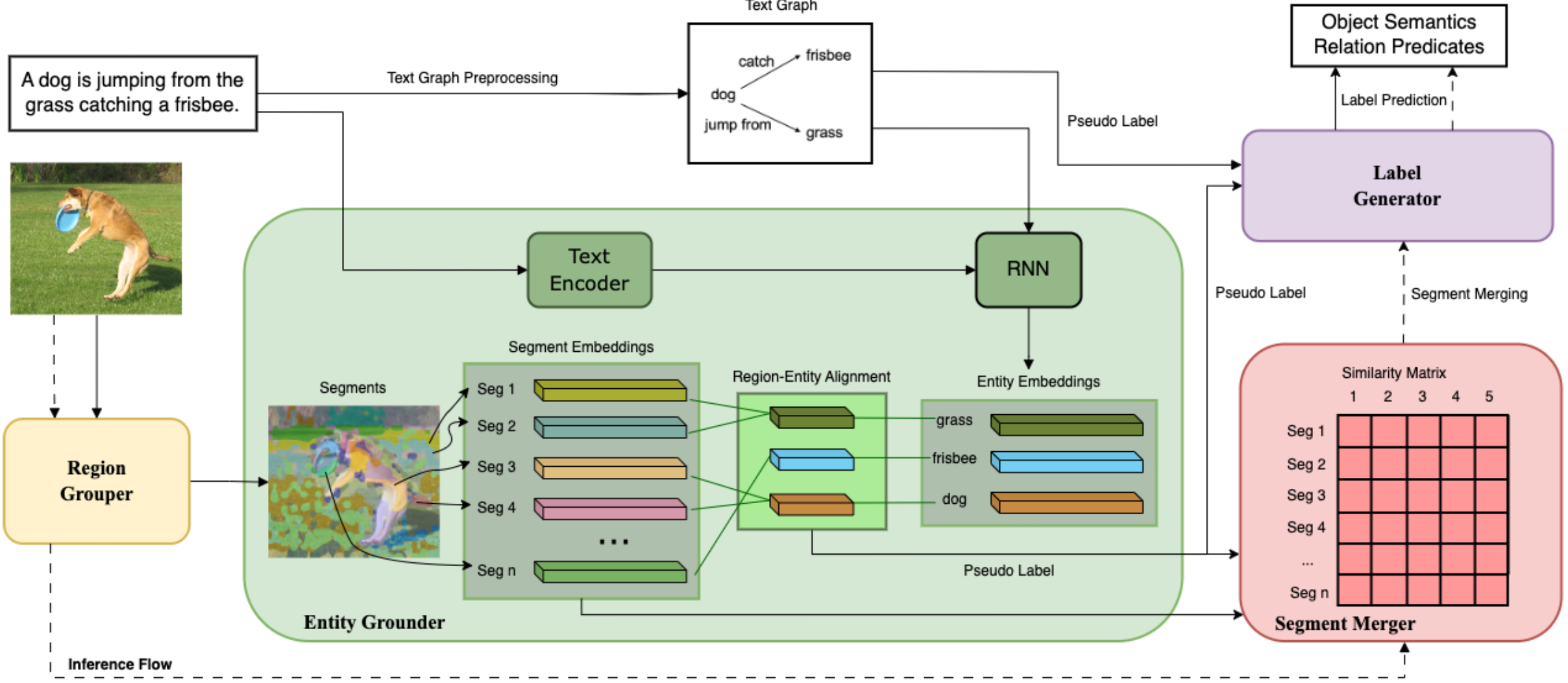
We provide typical qualitative results below to further show our framework's effectiveness.
Compared with
SGGNLS-o, our framework has the following advantages.
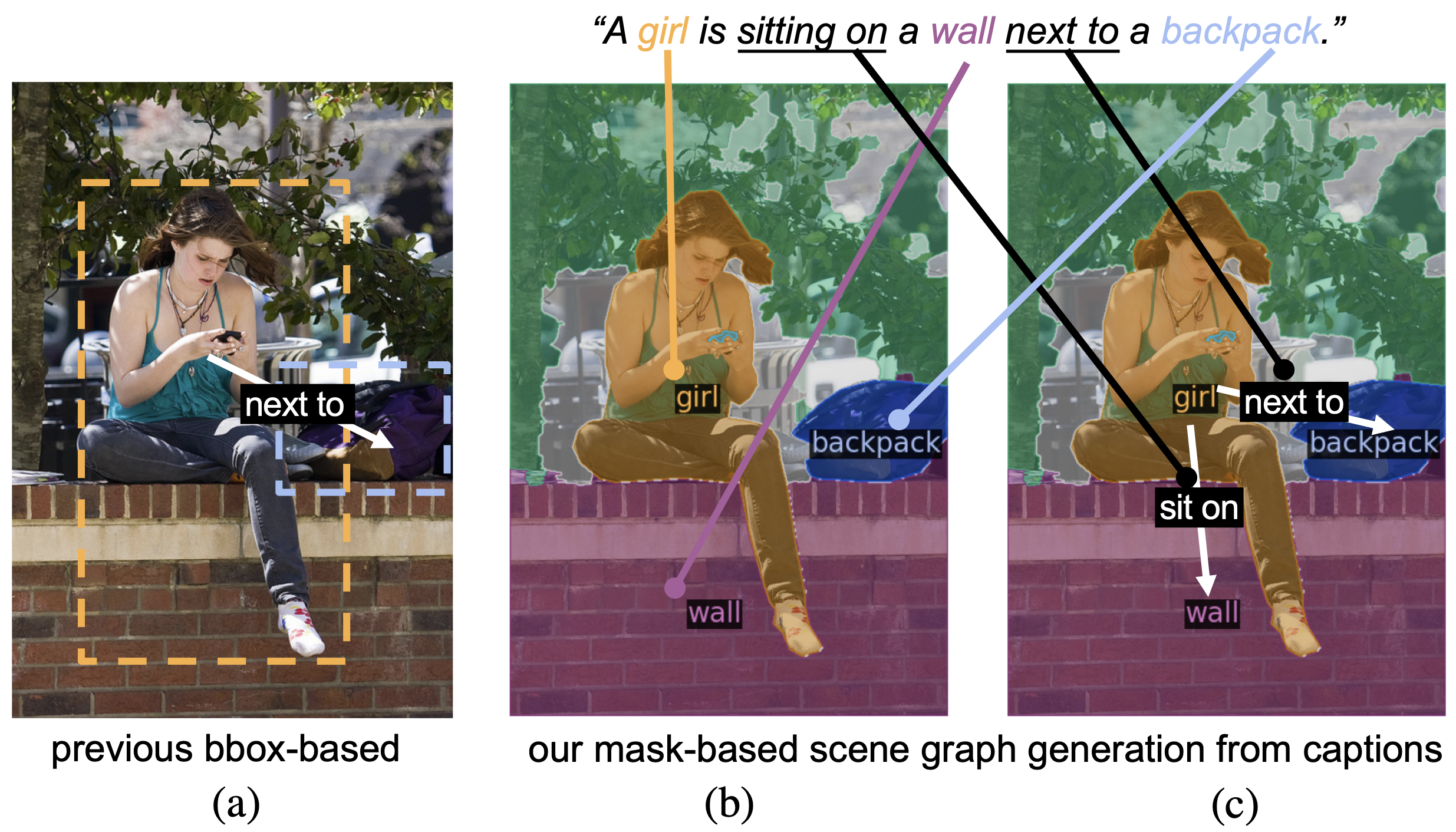
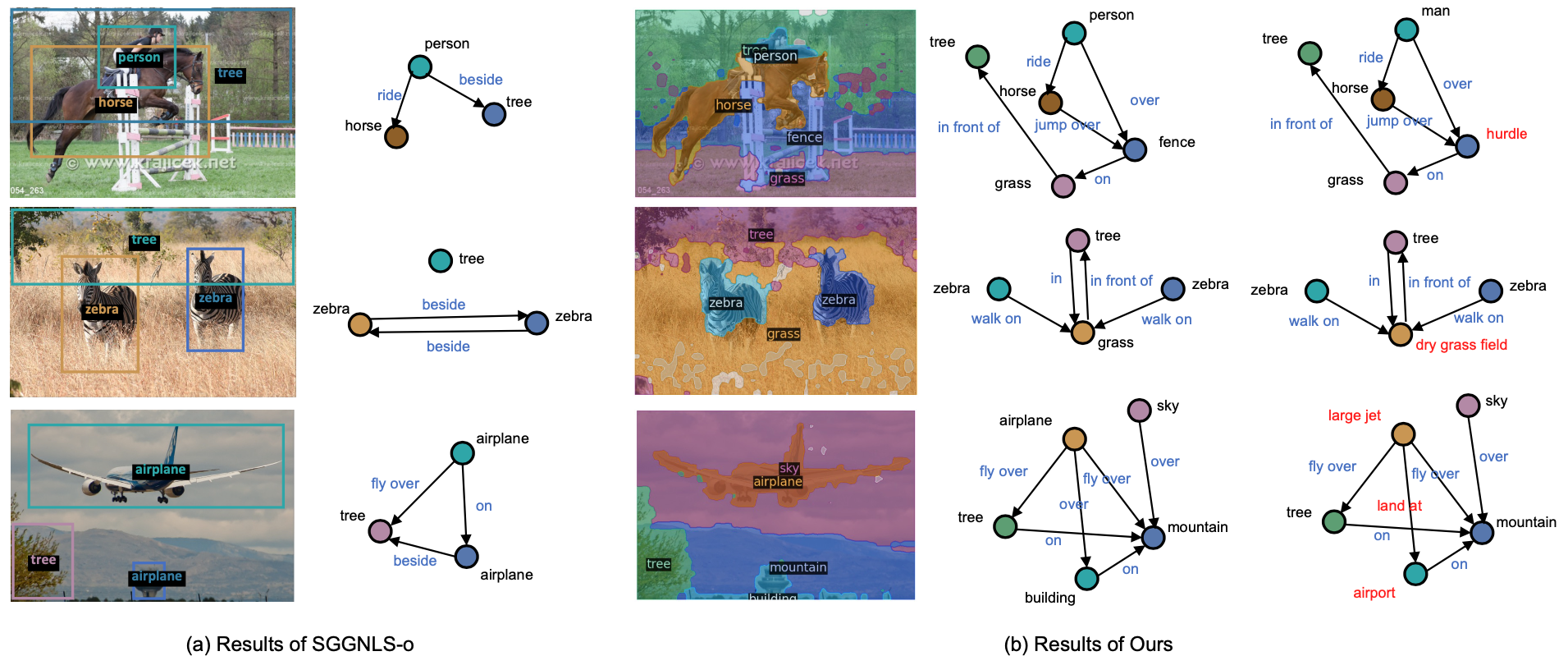
First, our framework is able to provide fine-grained semantic labels to each pixel in the image to reach a panoptic understanding, while
SGGNLS-o can only provide sparse bboxes produced by the pre-trained detector. Note that categories with irregular shapes (e.g., trees)
are hard to be labeled precisely by bboxes. Second, compared with
SGGNLS-o, our framework can generate more comprehensive object
semantics and relation predicates, such as
"dry grass field" and
"land at", showing the open-vocabulary potential of our framework.
More qualitative results can be found in the supplementary material.
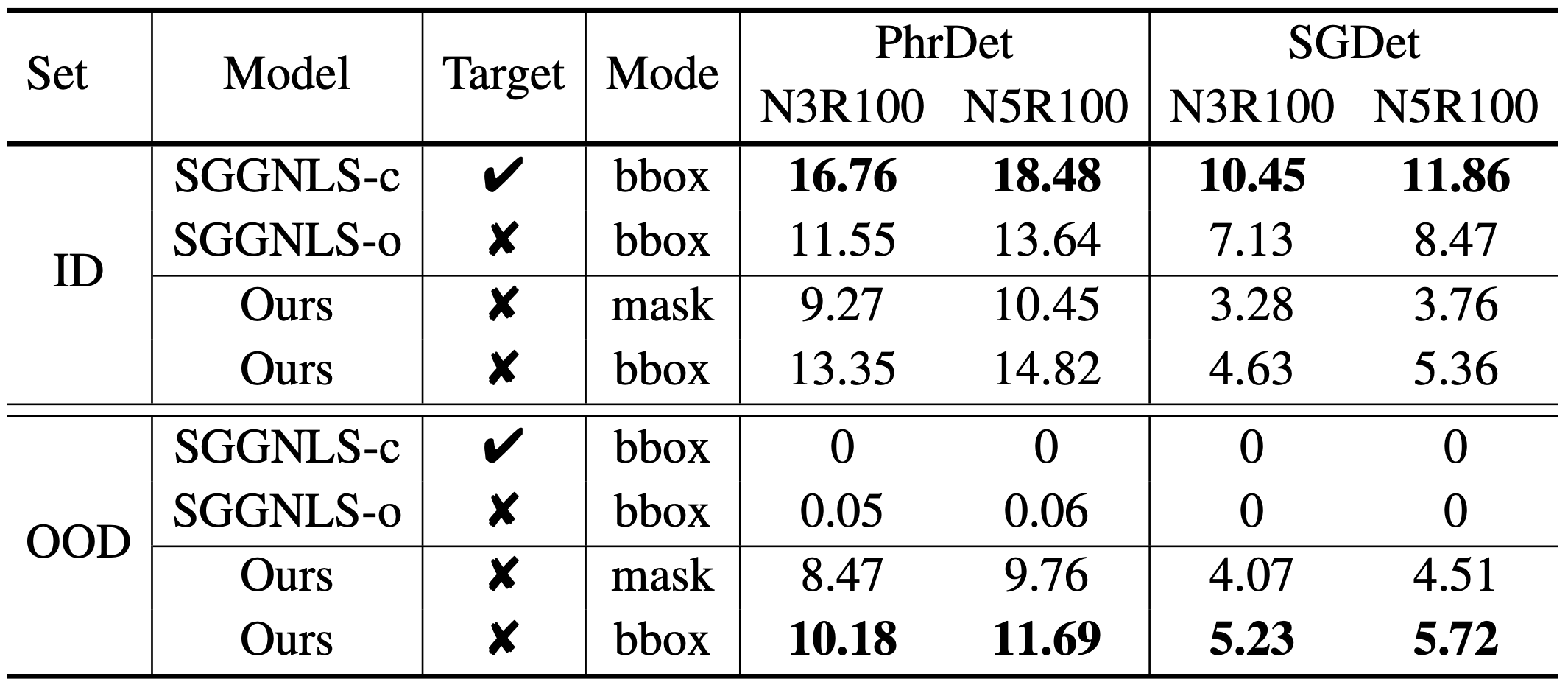
Out-of-distribution (OOD) Robustness
We further analyze another key advantage of our framework, i.e., the robustness in OOD cases.
Since
SGGNLS-c and
SGGNLS-o both rely on a pre-trained detector to locate objects, their performance highly depends on whether
object semantics in the scene are covered by the detector.
Based on the object semantics covered by the detector, we split the ground truth triplets into an in-distribution (ID) set and an OOD set. For
triplets within the ID set, both the subject and object semantics are covered, while for triplets in the OOD set, at least one of the semantics
is not covered.
As shown below, both
SGGNLS-c and
SGGNLS-o suffer a significant performance drop from the ID set to the OOD set. On the OOD set,
the triplets can hardly be retrieved. However, our framework, with the ability of location learned from purely text descriptions, can reach similar
performance on both sets, which demonstrates the OOD robustness of our framework for PSG generation.
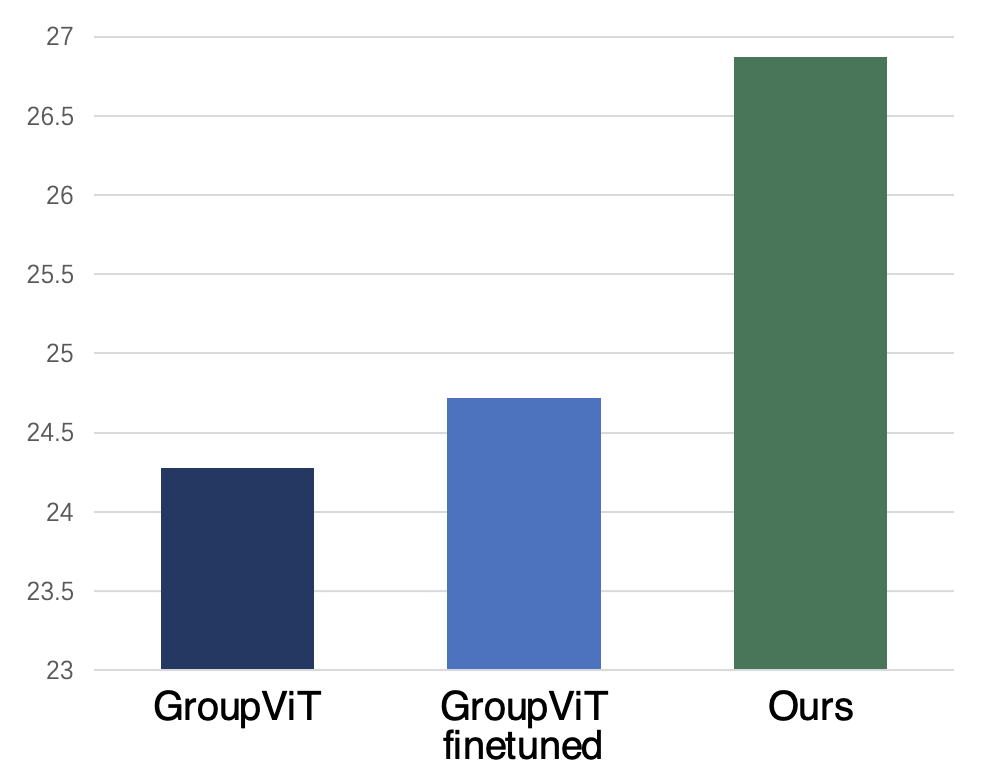
Application on Text-supervised Semantic Segmentation
As a side product, we observe that our entity grounder and segment merger can also enhance TSSS. Based on the original GroupViT, we replace the
multi-label contrastive loss with our entity grounder and segment merger. Then we finetune the model on the COCO Caption dataset.
As shown below, compared with GroupViT directly finetuned on the COCO Caption dataset, the explicit learning of merging in our modules can boost
the model with an absolute 2.15% improvement of mean Intersection over Union (mIoU, %) on COCO, which demonstrates the effectiveness of our proposed
modules on better object location.